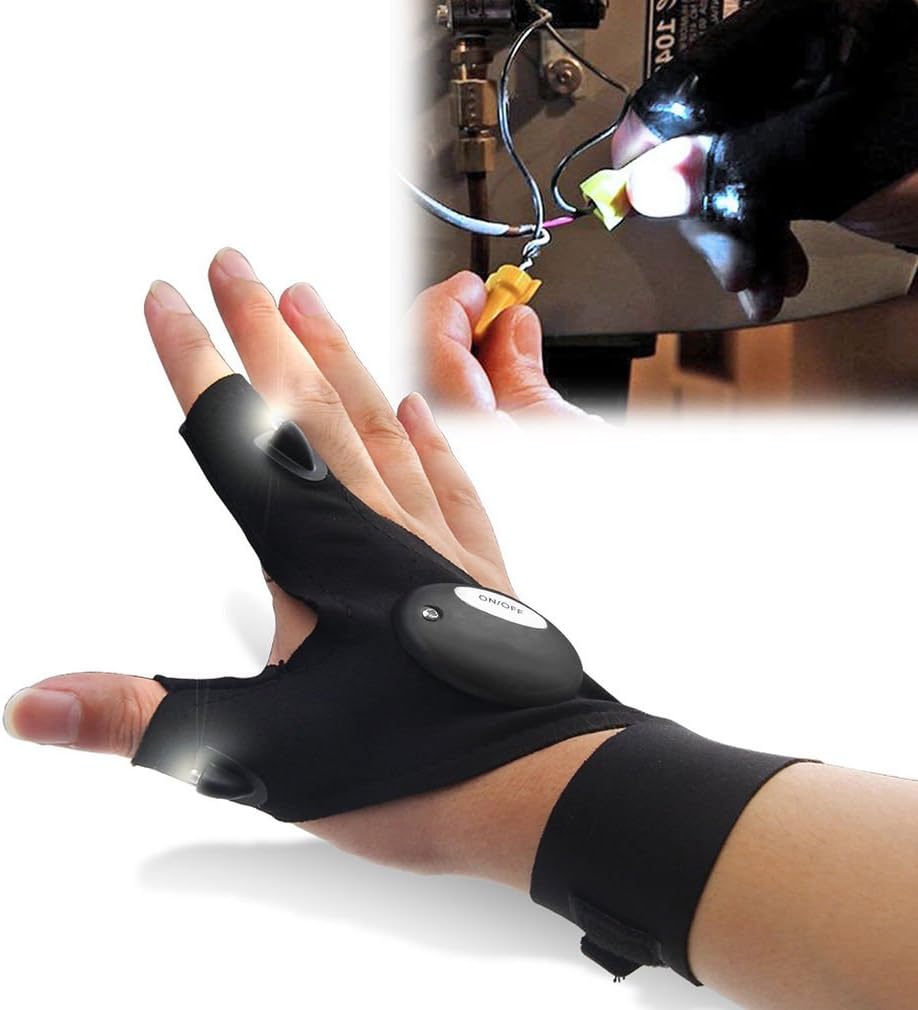
GLOVE TORCH Flashlight LED torch Light Flashlight Tools Fishing Cycling Plumbing Hiking Camping THE TORCH YOU CANT DROP Gloves 1 Piece Men's Women's Teens One Size fits all XTRA BRIGHT
£9.9£99Clearance
Shared by
ZTS2023
Joined in 2023
82
63
About this deal
I thought the Field function build_vocab() just builds its vocabulary from the training data. How are the GloVe embeddings involved here during this step? Dictionary mapping tokens to indices. insert_token ( token : str, index : int ) → None [source] ¶ Parameters :
GLOVE TORCH Flashlight LED torch Light Flashlight Tools
GLOVE TORCH Flashlight LED torch Light Flashlight Tools Fishing Cycling Plumbing Hiking Camping THE TORCH YOU CANT DROP Gloves... Description word_indices = torch.argmin(torch.abs(vec_seq.unsqueeze(1).expand(vs_new_size)- vecs.unsqueeze(0).expand(vec_new_size)).sum(dim=2),dim=1)But you set freeze=True. So, if you don't plan to retrain the embedding layer, then you'd probably do best with: Vectors -> Indices def emb2indices(vec_seq, vecs): # vec_seq is size: [sequence, emb_length], vecs is size: [num_indices, emb_length]
max_tokens – If provided, creates the vocab from the max_tokens - len(specials) most frequent tokens.RuntimeError – If an index within indices is not int range [0, itos.size()). set_default_index ( index : Optional [ int ] ) → None [source] ¶ Parameters :
USB Rechargeable Glove Flashlight Torch LED Lights - Etsy
Silicone Button - LED light set in the head of thumb and index finger that covered by silicone, effective prevent water ingress when fishing or rain. These fishing gloves use 2 x CR2016 button batteries that can be replaced easily by loosen the screw with a screwdriver. Beyond the first result, none of the other words are even related to programming! In contrast, if we flip the gender terms, we get very different results: print_closest_words(glove['programmer'] - glove['woman'] + glove['man']) Perfect gift for man] Birthdays, Christmas, Father's Day gift for any DIY, handyman, father, boyfriend, men, or women. This is a practical and creative gift, which will definitely surprise themOr, try a different but related analogies along the gender axis: print_closest_words(glove['king'] - glove['prince'] + glove['princess']) generating vocab from text file >>> import io >>> from torchtext.vocab import build_vocab_from_iterator >>> def yield_tokens ( file_path ): >>> with io . open ( file_path , encoding = 'utf-8' ) as f : >>> for line in f : >>> yield line . strip () . split () >>> vocab = build_vocab_from_iterator ( yield_tokens ( file_path ), specials = [ "" ]) Vectors ¶ class torchtext.vocab. Vectors ( name, cache = None, url = None, unk_init = None, max_vectors = None ) [source] ¶ __init__ ( name, cache = None, url = None, unk_init = None, max_vectors = None ) → None [source] ¶ Parameters : RuntimeError – If token already exists in the vocab forward ( tokens : List [ str ] ) → List [ int ] [source] ¶
*So you can easily identify outgoing links on our site, we've marked them with an "*" symbol. Links on our site are monetised, but this never affects which deals get posted. Find more info in our FAQs and About Us page.
 Joined in 2023
Joined in 2023  82
82  63
63
